
The Concept of Database Normalization
Imagine retrieving data from a huge database and all you find are errors, this is a sign to show that the data is messed up, to avoid that, let’s grasp a simple concept of Database Normalization.
We shall discuss Normalization, the problems that result without Normalization, how to resolve this issue using the first 3 forms of Normalization.
First, let’s get to know what normalization means.
What is Normalization?
Normalization is a technique of organizing data into multiple related tables to minimize data redundancy.
What is Data redundancy?
Repetition of similar data at multiple places.
Why would you reduce it?
- Reduce the size of the database.
- To avoid the 3 main problems i .e Insertion problems, Deletion problems and Updation problems.
Now that we know what normalization is, let’s look at the main 3 problems that result without Normalization.
The 3 main problems caused by Data Redundancy
- Insertion Anomaly
- Deletion Anomaly
- Updation Anomaly
To clarify these 3 problems, let’s take a look at this table.
| Student No | Student Name | Course | Office_tel | HOD |
| 1 | Sharon | CSC | 039112440 | Eng. Bainomugisha |
| 2 | Faith | CSC | 039112440 | Eng. Bainomugisha |
| 3 | Prisca | CSC | 039112440 | Eng. Bainomugisha |
Insertion Anomaly
To insert redundant data for every new row(Student Name from the above table) leads to insertion problems/anomalies.
Reason for repetition
- Two different but related data are stored in the same table.
- Deleting student information leads to deleting course information
- Course information is deleted along with Student data which leads to Deletion problems/Anomaly.
Deletion Anomaly
Loss of related data-set when some other data-set is deleted.
Updation Anomaly
Assuming Eng. Bainomuisha leaves and Mr X joins as the new HOD for CSC, as a result, the student administrator has to update all the student records with the new name of HOD(Mr. X). This leads to Updation Anomaly because the system administrator has to update a lot of data.
Imagine only one row is left out while updating the data, this will lead to data inconsistency. Hence Data Redundancy leads to Data Inconsistency.
Finally, here is how Normalization will resolve these problems.
How will Normalization solve these problems?
Normalization will break the existing student tables into 2 tables. Student table and Course table.
The student table will save the data of the student and the Course Table will save course data
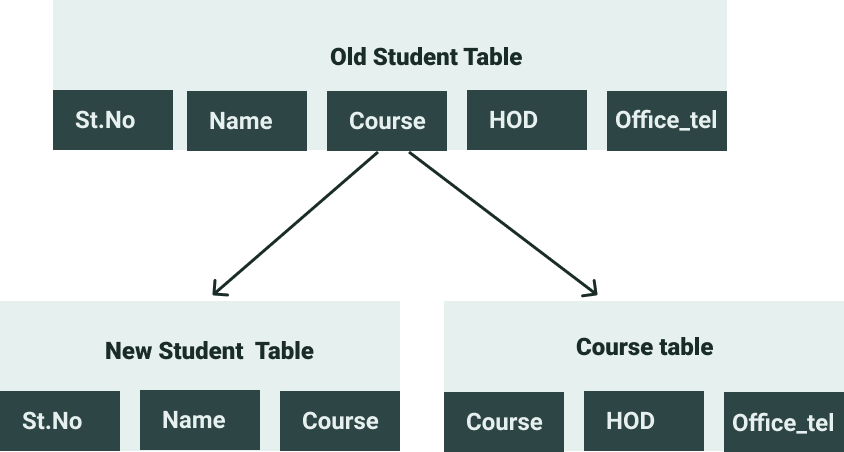
Qn.Isn’t Course Name still repeating in the tables?
Note that Normalization is not about Eliminating data redundancy but Minimizing data redundancy.
Our new tables now look like this.
Student Table
| Student No | Student Name | Course |
| 1 | Sharon | CSC |
| 2 | Faith | CSC |
| 3 | Prisca | CSC |
Course Table
| Course | Office_tel | HOD |
| CSC | 039112440 | Eng. Bainomugisha |
| CSC | 039112440 | Eng. Bainomugisha |
| CSC | 039112440 | Eng. Bainomugisha |
- To insert new data, we only enter the Student No, Student Name and Course Name and . Course information is already stored in the Course table, we don’t have to update or insert it again.
- If you want to store new student information, you can delete all the student’s records and you still have course information not deleted.
- To update the HOD and Office tel, we just do it in one place.
Types of Normalization
1st Normal Form 1NF-Step 1 of the Normalization
Design your table in such a way that can be extended.
Every Database should be at least in 1NF or else it is taken to be a bad Database Design.
How to achieve 1NF, 4 basic rules.
- Firstly, each column in the table should contain single values, not multiple values.
- Secondly, each column should contain a value of the same type.
- Thirdly, each column should have a unique name- to avoid confusion in the time of retrieving data.
- In addition, the order in which data is saved doesn’t matter.
Example1. Rule No.1 is being violated in column 3
| Student No. | Student Name | Subject |
| 101 | Sharon | DBD, PHP |
| 102 | Faith | DBD |
| 103 | Prisca | PHP, JS |
INF-Resolve the issue
| Student No. | Student Name | Subject |
| 101 | Sharon | PHP |
| 102 | Faith | DBD |
| 103 | Prisca | PHP |
| 101 | Sharon | PHP |
| 103 | Prisca | JS |
2nd Normal Form, 2NF-Step2 of Normalizaion
2 Conditions must be fulfilled
- Firstly, the table must be in 1NF
- Secondly, it should not have any Partial Dependencies
What is Partial Dependency?
Let’s have a look at this table.
| Student No. | Student Name | reg_no | Course | Address |
| 1 | Sharon | 101 | CSC | KLA |
| 2 | Sharon | 221 | CSC | KLA |
| 3 | Faith | 214 | SE | MUK |
| 4 | Prisca | 169 | IT | JJ |
| 5 | Cynthia | 441 | EE | KR |
Assuming you have the same student names, you can easily fetch data using the student_id which could be the primary key.
A primary key is a column/group of columns that can uniquely identify each row in a table.
For example Course Name of a student with id 5- EE
Name of the student with id 5- Cynthia
Imagine we have 2 more tables, a subject table to store subjects and a score table to store marks for the students. This will result to;
| score_id | subject_id | student_id | marks | teacher_name |
| 1 | 1 | 101 | 95 | Mr. Js |
| 2 | 2 | 101 | 82 | Mr. Js |
| 3 | 3 | 214 | 78 | Mr.PHP |
| 4 | 4 | 214 | 80 | Mr.PHP |
| 5 | 5 | 214 | 76 | Mr. DBD |
Qn. Get marks of student with student id 101
You don’t know for which subject and if given a subject id, you don’t know for which student hence we need student_id and subject_id together to uniquely identify any row of data in the SCORE table because we have a many to many relationships meaning:
- One student can opt for more than one subject.
- One subject can be opted for by more than one student.
The teacher’s name only depends on the subject. It has nothing to do with student_id. This is partial dependency. To eliminate partial dependency, we have to remove teacher_name from the score table.
You can move the teacher_name to the subject table.
You can also create another table called teacher table with teacher_id and teacher_name and use the teacher_id whenever u want.
| subject_id | student_name | Teacher |
| 1 | JS | Mr. JS |
| 2 | PHP | Mr. PHP |
| 3 | DBD | M. DBD |
| 4 | JS | Mr. JS |
| teacher_id | teacher_name |
| 1 | Mr. JS |
| 2 | Mr. PHP |
| 3 | M. DBD |
3rd Normal Form 3NF
Conditions for 3NF
- Firstly, the table should be in 2nd Normal form
- Secondly, the table should have a transitive dependency.
Adding exam name and total marks to the score table
| score_id | subject_id | student_id | marks | exam_name | total_marks |
| 1 | 1 | 101 | 90 | Baino | 95 |
| 2 | 2 | 101 | 82 | Baino | 85 |
| 3 | 3 | 214 | 78 | Grace | 88 |
| 4 | 4 | 214 | 80 | Grace | 78 |
| 5 | 5 | 214 | 68 | Eng | 76 |
Subject_id and student_id are primary keys so other columns depend on it except Total marks which depend on exam name but exam name is not part of our primary keys. This is a transitive dependency
Solution.
Get exam_name and total_marks, put them in an exam table and use exam_id whenever required.
| exam_name | total_marks |
| DBD1 | 9O |
| DBD2 | 85 |
| PHP1 | 88 |
| PHP2 | 78 |
| JS | 68 |
Score table in 3NF
| score_id | subject_id | student_id | marks | exam_name |
| 1 | 1 | 101 | 95 | DBD1 |
| 2 | 2 | 101 | 82 | DBD2 |
| 3 | 3 | 214 | 78 | PHP1 |
| 4 | 4 | 214 | 80 | PHP2 |
| 5 | 5 | 214 | 76 | JS |
We’ve made it!!!
In conclusion, 1st Normal Form, 2nd Normal Form and 3rd Normal Form are the three ways that you can prevent issues that come along with data redundancy.


